
Effective Deep Learning is possible
Nowadays, when Deep Learning libraries such as Keras makes composing Deep Learning networks as easy task as it can be one important aspect still remains quite difficult. This aspect that you could have guessed is the tuning of various number, which isn’t small at all, of hyper-parameters. For instance, network capacity which is number of neurons and number of layers, learning rate and momentum, number of training epochs and batch size and the list goes on. But now it may become a less of a hassle since a new Better Deep Learning book by Jason Brownlee focuses exactly on the issue of tuning hyper-parameters as best as possible given a task in hand.
Why is it worth reading this book?
When I myself worked through this book from the beginning to the end, I liked that this book as other books written by Jason Brownlee followed the familiar path of self-contained chapters that provided just enough theory and detailed practical working examples, that might be extended and build upon by practitioners. The code samples themselves are concise and can be run on an average PC without a need in GPU, but nevertheless they convey very well what author intended to show.
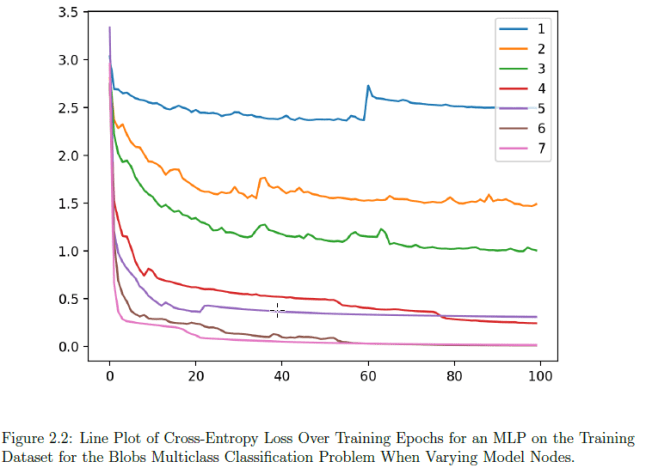
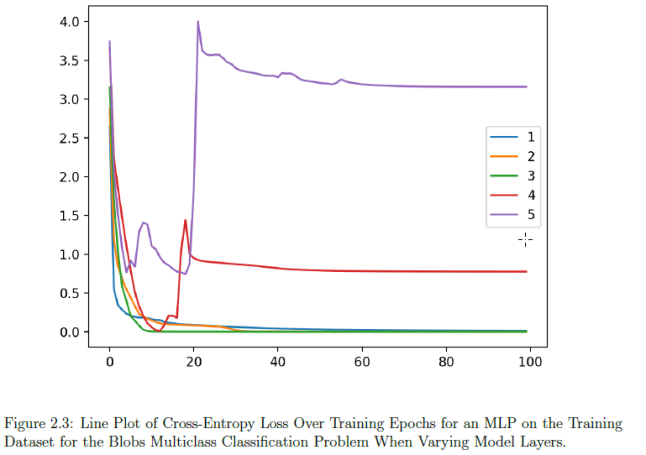
While playing with code samples in each chapter I found myself thinking that I was back at college again doing a lab for electrical engineering. I felt this way since each chapter provides a great number of experiments with related graphs that help understand the hyper-parameter behavior in different configurations.
How this book may help me?
Better Deep Learning may help you if you have initial experience with Deep Learning networks and you want to fine tune network performance in a more controlled way than simple trial and error. Since the book uses restricted and simple data-sets generated with Python libraries it is easy to run each experiment and get fast understanding how each hyper-parameter effects network behavior.
In addition to working code examples, the book provides a number of focused references to papers, books and other materials that are related to the content of each chapter.
Last but not least, each chapter concludes with a number of extensions that make a practitioner think harder and try to play with the chapter’s content in a much more deeper level.
Conclusion
All in all, the book provides comprehensive treatment of all hyper-parameters you may find in various types of Deep Learning networks, such as CNN, RNN, LSTM and it makes it clear that fine tuning of Deep Learning is possible even for a beginner with proper guidance which the book provides.
Stay fine tuned!
